Realistic speech data applications in Machine Learning
Lab41, in collaboration with SRI International, recently introduced a speech data-set, Voices Obscured in Complex Environmental Settings(VOiCES). VOiCES is the first open source speech data-set recorded in real environments with far-field microphones, capturing reverberant acoustics and background noise. We recently released a video explaining how and why we created this data-set:
Since there are limited open-source speech audio data-sets with background noise, it is common practice to digitally blend clean speech with background audio and/or room acoustics. However, this approach limits predictive model performance on real noisy audio data. The VOiCES data-set can therefore be used to improve machine learning system performance in a range of audio ML tasks, since it is closer to what the model will see during inference. Relevant audio ML tasks include speech processing, audio classification, and acoustic signal processing.
In this blog post, we share a section of our recent tutorial on creating a simple predictive model with the VOiCES data, as well as a few recent applications. These applications include our own recent work in secure machine learning, a winning UCSD hackathon project on speech extraction, and an upcoming challenge at InterSpeech.
Realistic audio data
Before we discuss the applications, let’s dig in to the data. The VOiCES data-set captures many sources of variance between voice recordings: it is recorded in multiple rooms, with different types and locations of microphone, and several types of distractor noises. A full description of the data-set can be found here.
Listen to a sample recording without background noise:
You can hear what reverb sounds like in the above sample, recorded with a wall lavalier microphone: it sounds muffled and distant.
Now listen to the same speech recording with babble in the background:
It kind of sounds like someone reading a book aloud at a crowded cocktail party. Let’s see what the audible differences between the 2 audio files look like:
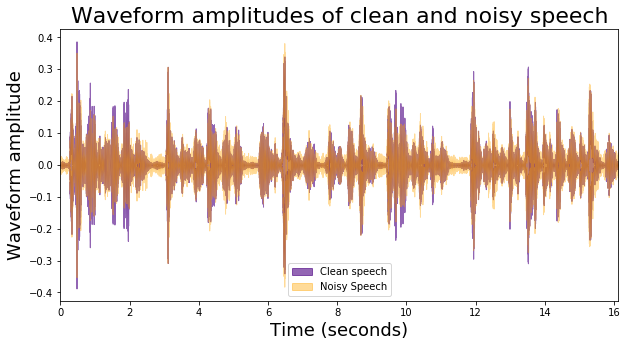
The above waveform amplitudes visualize the quiet din of babble during quiet pauses, as well as the occasional crispness of the clean speech.
Feature generation
To train predictive machine learning models on audio data, we must first generate features from wav files. Audio signals are commonly transformed into two-dimensional time frequency representations for processing. Frequency space is used for identifying speech, speakers, or speaker qualities, since there is considerable individual variance therein. A common method for feature generation is with a Fourier transformation:
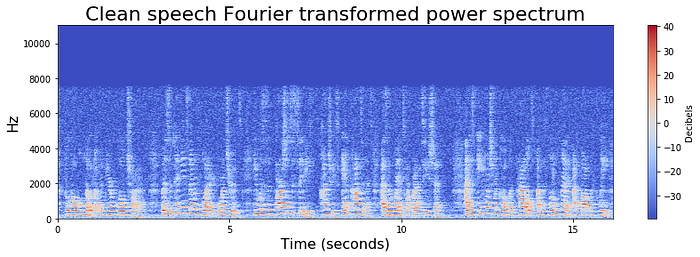
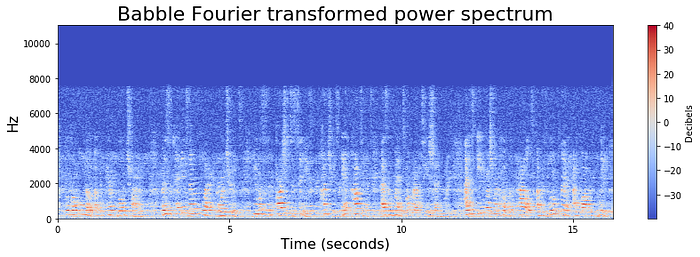
These plots illustrate how most of the high-decibel activity is at the very bottom of the frequency spectrum. The bottom figure demonstrates the challenge in distinguishing between speech and background babble.
In contrast to a Fourier transformation, Mel-Frequency analysis is derived from human perception experiments. The human auditory system acts as a frequency filter. These filters are non-uniformly spaced on the frequency axis, with more filters in the low frequency regions corresponding to where human speech is heard. Below are Mel-transformed spectrograms of the above data:
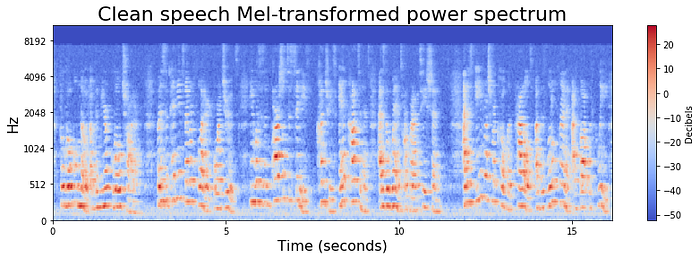
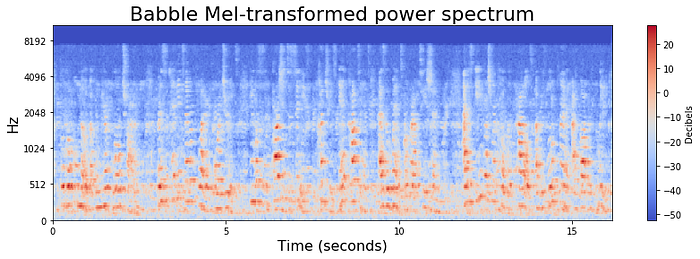
These Mel spectrograms provide much higher resolution at human speech frequencies. Now we can create a simple model that can learn from these features. To train the below model, we generated features in 12 Mel bands, as well as other statistical properties of speech.
Gender ID model
To predict gender (GID) from Mel bands, we trained the logistic regression classifier (LR) and random forest classifier (RFC) available in scikit-learn. Gender is a binary variable in our data-set. Before training a predictive model, we further processed these data:
We didn’t shuffle the train and test data in order to maintain an even comparison between models, which is why we employed the interleaving process instead of simply concatenating the two gender dataframes. With these balanced data, we trained our two simple ML models.

The GID models learned which features were most predictive for our label, speaker gender. We tested the models’ performance on a held out subset of the data, to observe how accurately it predicted an unheard speaker’s gender. The RFC had the strongest results, and was also overfitting considerably (as evidenced by the train-test accuracy disparity). To improve performance, we performed a hyperparameter search:
Our hyperparameter search improved our performance from 88.8% test accuracy to 91.3%.
The above code and figures were developed for a tutorial at the UCSD HardHacks hackathon, held in January 2019. The full jupyter notebook and data subset can be found through the below link:
VOiCES applications
Membership Inference
Some of our recent work in secure machine learning used the VOiCES data-set. We previously wrote about membership inference attacks on computer vision models and model inversion attacks on computer vision models. Most recently, we wrote about membership inference attacks on speaker identification models. For this work, we created both a speaker identification model (SID) and a membership inference model to attack it. The goal of a membership inference (MI) attack is to determine if a sample of data was used in a predictive model’s training data-set. This type of attack can compromise the privacy of members enrolled in an SID system by revealing their participation in the institution using their voice as a verification key, e.g. a particular bank. Membership inference attacks can also provide an entering point to forge and use this biometric key for nefarious purposes.
SID is a similar classification process to the gender identification model detailed above. However, instead of classifying using a binary gender label, we classified the speaker’s identity. This increase in both the number of labels and the feature resolution required a deeper machine learning model. We implemented a CNN in PyTorch, testing the accuracy of the SID model and membership inference attacks following several defenses. We performed these tests on both clean and noisy audio data, and found that the efficacy of defenses differed between the two data sets. The code for these results is available in our Cyphercat API repository.
Denoising with VOiCES
Lastly, we will describe recent work in denoising the VOiCES data-set. We recently provided some background on the utility of VOiCES for denoising. This past January, a team at UCSD’s HardHacks hackathon used VOiCES to create the Crisp Speech project, which extracted clean speech from noisy audio. This novel project won several prizes at the Hackathon.
We were very excited about the Crisp Speech Hackathon project, which combined a DragonBoard 410C with a speech-denoising wavenet trained on VOiCES data. The DragonBoard was used to capture audio in real-time, denoise the audio recording, and play back clean speech. The demo was very impressive, and the team swept the Hackathon competition! They won Lab41’s first place prize, for best application for audio machine learning. In addition, they won Linaro’s prize for best use of open source tools, and TI’s second place prize. This project was also very relevant to the hackathon theme: projects for public good and societal benefit. Speech denoising is a significant concern for the approximately 20% of Americans who have hearing loss.
Watch this space for an update from the VOiCES from a distance challenge at InterSpeech, in September 2019. This challenge focuses on benchmarking and further improving state-of-the-art technologies in the area of speaker recognition and automatic speech recognition (ASR) for far-field speech.
We hope the above code and examples give you a starting point and directions for how to use the VOiCES data in your work. Comment below to reach out! VOiCES is open source, for both academic and commercial use.

